Google Summer of Code 2011 gave a big boost to the development of the SHOGUN machine learning toolbox. In case you have never heard of SHOGUN or machine learning, machine learning involves algorithms that do ‘intelligent’ and even automatic data processing and is currently used in many different settings. You will find machine learning in the face detection in your camera, compressing the speech in your mobile phone, and powering the recommendations in your favorite online shop, as well as predicting the solubility of molecules in water and the location of genes in humans, to name just a few examples. Interested? Shogun can help you give it a try.
SHOGUN is a machine learning toolbox, which is designed for unified large-scale learning for a broad range of feature types and learning settings. It offers a considerable number of machine learning models such as support vector machines for classification and regression, hidden Markov models, multiple kernel learning, linear discriminant analysis, linear programming machines, and perceptrons. Most of the specific algorithms are able to deal with several different data classes, including dense and sparse vectors and sequences using floating point or discrete data types. We have used this toolbox in several applications from computational biology, some of them coming with no less than 10 million training examples and others with 7 billion test examples. With more than a thousand installations worldwide, SHOGUN is already widely adopted in the machine learning community and beyond.
Some very simple examples stemming from a sub-branch of machine learning called supervised learning illustrate how objects represented by two-dimensional vectors can be classified into good or bad, by learning a support vector machine. I would suggest installing the python_modular interface of SHOGUN and to run the example interactive_svm_demo.py also included in the source tarball. Two images illustrating the training of a support vector machine follow:
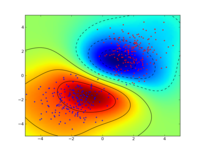
We were a first time organization this year, i.e. taking part in our first Google Summer of Code. Having received many student applications, we were very happy to hear that we were given 5 very talented students but we had to reject about 60 students (only 7% acceptance rate). Deciding which 5 students we would accept was an extremely tough decision for us. So in the end we raised the bar by requiring sample contributions even before the actual Google Summer of Code started. The quality of the contributions and independence of the student aided our decision on the selection of the final five students.
At the end of the summer we now have a new core developer and various new features implemented in SHOGUN: Interfaces to new languages like Java, C#, Ruby, and Lua, a model selection framework, many dimension reduction techniques, Gaussian Mixture Model estimation and a full-fledged online learning framework. All of this work has already been integrated in the newly released shogun 1.0.0. To find out more about the newly implemented features read below.
Interfaces to the Java, C#, Lua and Ruby Programming Languages
Baozeng
Boazeng implemented swig-typemaps that enable transfer of objects native to the language one wants to interface to. In his project he added support for Java, Ruby, C# and Lua. His knowledge about Swig helped us to drastically simplify shogun's typemaps for existing languages like Octave and Python, resolving other corner-case type issues. In addition, the typemaps bring a high-performance and versatile machine learning toolbox to these languages. It should be noted that shogun objects trained in e.g. Python can be serialized to disk and then loaded from any other language like Lua or Java. We hope this helps users working in multiple-language environments. Note that the syntax is very similar across all languages used, compare for yourself, various examples for all languages (Python, Octave, Java, Lua, Ruby, and C#) are available.
Cross-Validation Framework
Heiko Strathmann
Nearly every learning machine has parameters which have to be determined manually. Before Heiko started his project, one had to manually implement cross-validation using (nested) for-loops. In his highly involved project Heiko extended shogun's core to register parameters and ultimately made cross-validation possible. He implemented different model selection schemes (train, validation, test split, n-fold cross-validation, stratified cross-validation, etc.) and created some examples for illustration. Note that various performance measures are available to measure how “good” a model is. The figure below shows the area under the receiver operator characteristic curve as an example.
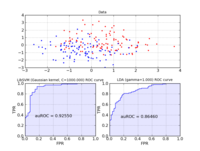
Dimension Reduction Techniques
Sergey Lisitsyn
Dimensionality reduction is the process of finding a low-dimensional representation of a high-dimensional one while maintaining the core essence of the data. For one of the most important practical issues of applied machine learning, it is widely used for preprocessing real data. With a strong focus on memory requirements and speed, Sergey implemented the following dimension reduction techniques:
- Locally Linear Embedding
- Kernel Locally Linear Embedding
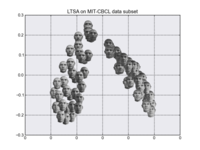
- Local Tangent Space Alignment
- Multidimensional scaling (with capability of landmark approximation)
- Isomap
- Hessian Locally Linear Embedding
- Laplacian Eigenmaps
See below for some illustrations of dimension reduction/embedding techniques.





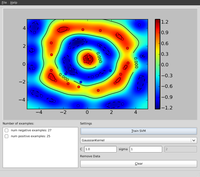
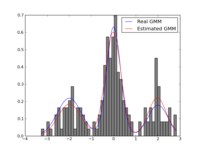
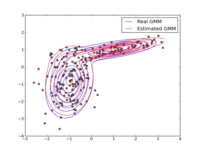
Expectation Maximization Algorithms for Gaussian Mixture Models
Alesis Novik
The Expectation-Maximization algorithm is well known in the machine learning community. The goal of this project was the robust implementation of the Expectation-Maximization algorithm for Gaussian Mixture Models. Several computational tricks have been applied to address numerical and stability issues, like:
Representing covariance matrices as their SVD
Doing operations in log domain to avoid overflow/underflow
Setting minimum variances to avoid singular Gaussians
Merging/splitting of Gaussians.
An illustrative example of estimating a one and two-dimensional Gaussian follows below.
Large Scale Learning Framework and Integration of Vowpal Wabbit
Shashwat Lal Das
Shashwat introduced support for 'streaming' features into shogun. That is, instead of shogun's traditional way of requiring all data to be in memory, features can now be streamed from a disk, enabling the use of massively big data sets. He implemented support for dense and sparse vector based input streams as well as strings and converted existing online learning methods to use this framework. He was particularly careful and even made it possible to emulate streaming from in-memory features. He finally integrated (parts of) Vowpal Wabbit, which is a very fast large scale online learning algorithm based on SGD.
No comments:
Post a Comment