In this post, we focus on GAE and share some techniques that have been useful in the migration process.
Task failure management
Our application makes heavy use of the Task Queue service, and must detect and manage tasks that are being retried multiple times but aren’t succeeding. To do this, we extended
Deferred, which allows easy task definition and deployment. We defined a new Task abstraction, which implements an extended Deferrable and requires that every Task implement an onFailure method. Our extension of Deferred then terminates a Task permanently if it exceeds a threshold on retries, and calls its onFailure method.This allows permanent task failure to be reliably exposed as an application-level event, and handled appropriately. (Similar techniques could be used to extend the new official Deferred API).
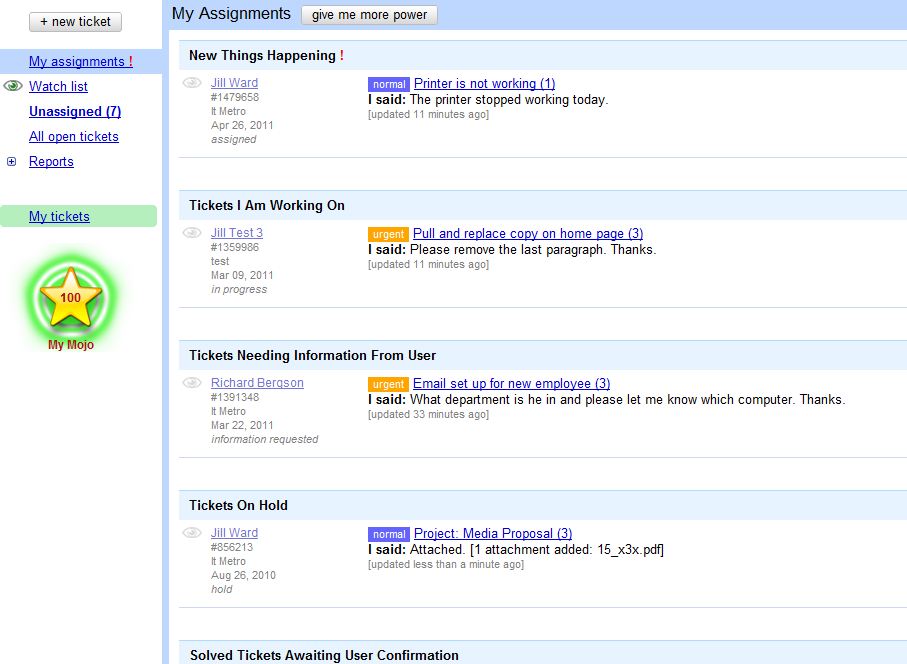 |
| From the existing Mojo Helpdesk: a view of a user’s assigned tickets. |
Mojo Helpdesk needs to run many types of batch jobs, and
appengine-mapreduce is of great utility. However, we often want to map over a filtered subset of Datastore entities, and our map implementations are JDO-based (to enforce consistent application semantics), so we don’t need low-level Entities prefetched.
So, we made two extensions to the mapper libraries. First, we support the specification of filters on the mapper’s Datastore sharding and fetch queries, so that a job need not iterate over all the entities of a Kind. Second, our mapper fetch does a keys-only Datastore query; only the keys are provided to the map method, then the full data objects are obtained via JDO. These changes let us run large JDO-based mapreduce jobs with much greater efficiency.Supporting transaction semantics
The Datastore supports transactions only on entities in the same entity group. Often, operations on multiple entities must be performed atomically, but grouping is infeasible due to the contention that would result. We make heavy use of transactional tasks to circumvent this restriction. (If a task is launched within a transaction, it will be run if and only if the transaction commits). A group of activities performed in this manner – the initiating method and its transactional tasks – can be viewed as a “transactional unit” with shared semantics.
We have made this concept explicit by creating a framework to support definition, invocation, and automatic logging of transactional units. (The
Task abstraction above is used to identify cases where a transactional task does not succeed). All Datastore-related application actions – both in RPC methods and "offline" activities like mapreduce – use this framework. This approach has helped to make our application robust, by enforcing application-wide consistency in transaction semantics, and in the process, standardizing the events and logging which feed the app’s workflow systems.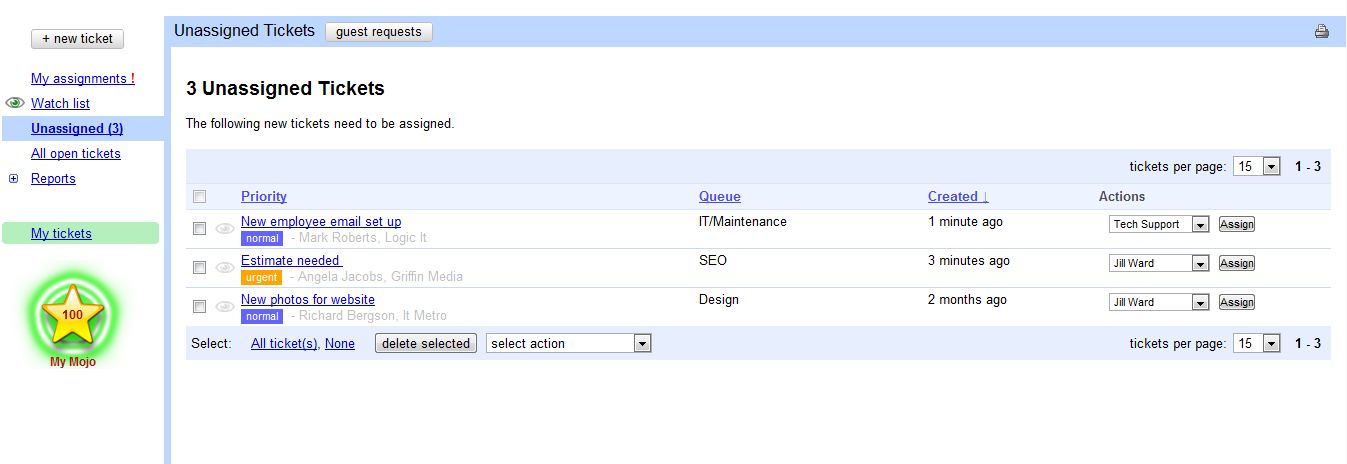 |
| From the existing Mojo Helpdesk: a view of the unassigned tickets for a work group. |
To support join-like functionality, we can exploit multi-valued Entity properties (list properties) and the query support they provide. For example, a
Ticket includes a list of associated Tag IDs, and Tag objects include a list of Ticket IDs they’re used with. This lets us very efficiently fetch, for example, all Tickets tagged with a conjunction of keywords, or any Tags that a set of tickets has in common. (We have found the use of "index entities" to be effective in this context). We also store derived counts and categorizations in order to sidestep Datastore restrictions on query formulation.
No comments:
Post a Comment